
【剑指Offer I】38. 字符串的排列
题目
输入一个字符串,打印出该字符串中字符的所有排列。
你可以以任意顺序返回这个字符串数组,但里面不能有重复元素。
输入:s = “abc”
输出:[“abc”,”acb”,”bac”,”bca”,”cab”,”cba”]
解答
字符串中可能含有重复的字符,在求全排列时,需要去重。如果是对结果集去重,首先会有大量重复的遍历浪费时间,其次对于字符串数组的去重也挺浪费时间的。所以最好是在DFS过程中对会产生重复结果的分支进行剪枝。
或者使用下一个排列的技巧,从初始排列一直求到最后一个排列,这种方法保证不会有重复的排列。
方法一 全排列去重
- 对原字符串排序,使得重复的字符排在一起;
- 递归放置每个位置上的字符,
dfs(s, i, perm),枚举下一个可能的字符:- 根据使用状态和与前一个字符的比较结果,先进行剪枝;
- 保存当前层的状态和结果;
- 递归放置下一个位置的字符,
dfs(s, i+1, perm); - 回溯,恢复到上一层的状态。
- 每个位置都放置过字符,则当前分支结束,保存分支结果,退出递归。
tips1 回溯技巧
递归和回溯的代码应该是对称的,先修改状态,再递归下一层,最后恢复状态:
1 | used[j] = true; // 标记已使用 |
tips2 剪枝原理
!used[j-1] && s[j-1] == s[j],用这个条件剪枝意味着在一个位置(同一层)上选择字符时只会选择重复字符中第一个未被使用的。这样就保证了重复字符在排列结果中的顺序一定满足原顺序。搜索树如下图,重复的字符是跟同一层的兄弟节点比较,因此这种方法可以剪去更多的多分支子树。
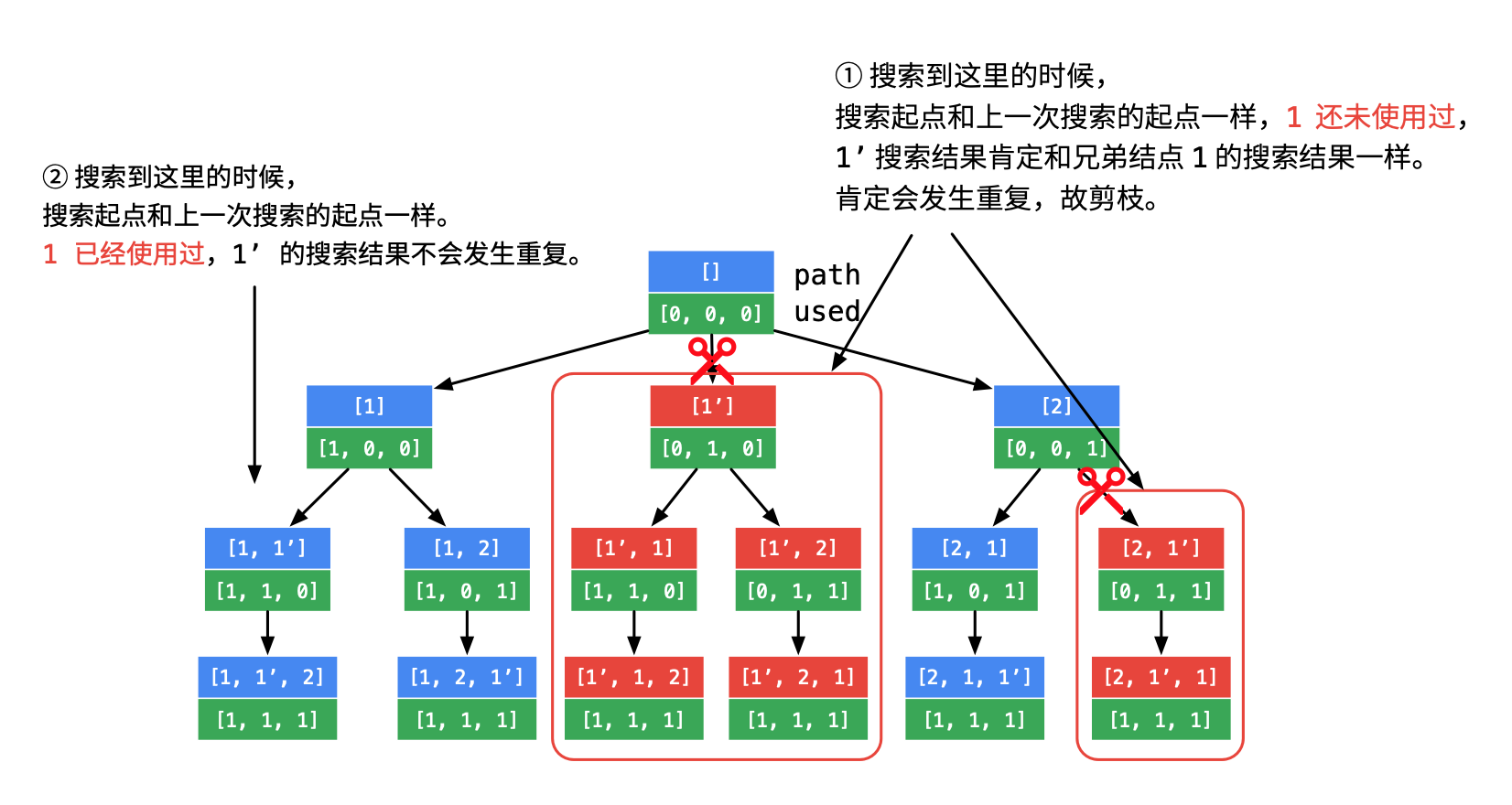
以 abb’c 为例,排列结果只可能出现 bb’,而不可能出现 b’b。
used[j-1] && s[j-1] == s[j],用这个条件剪枝意味着在一次完整放置(同一个分支)中选择字符时不会选择使用过的字符的下一个重复字符。这样保证重复字符在排列结果中的顺序一定是逆序的。搜索树(部分)如下图,重复的字符是跟同一分支的父亲节点比较,因此这种方法可能要到叶子节点才能剪枝。
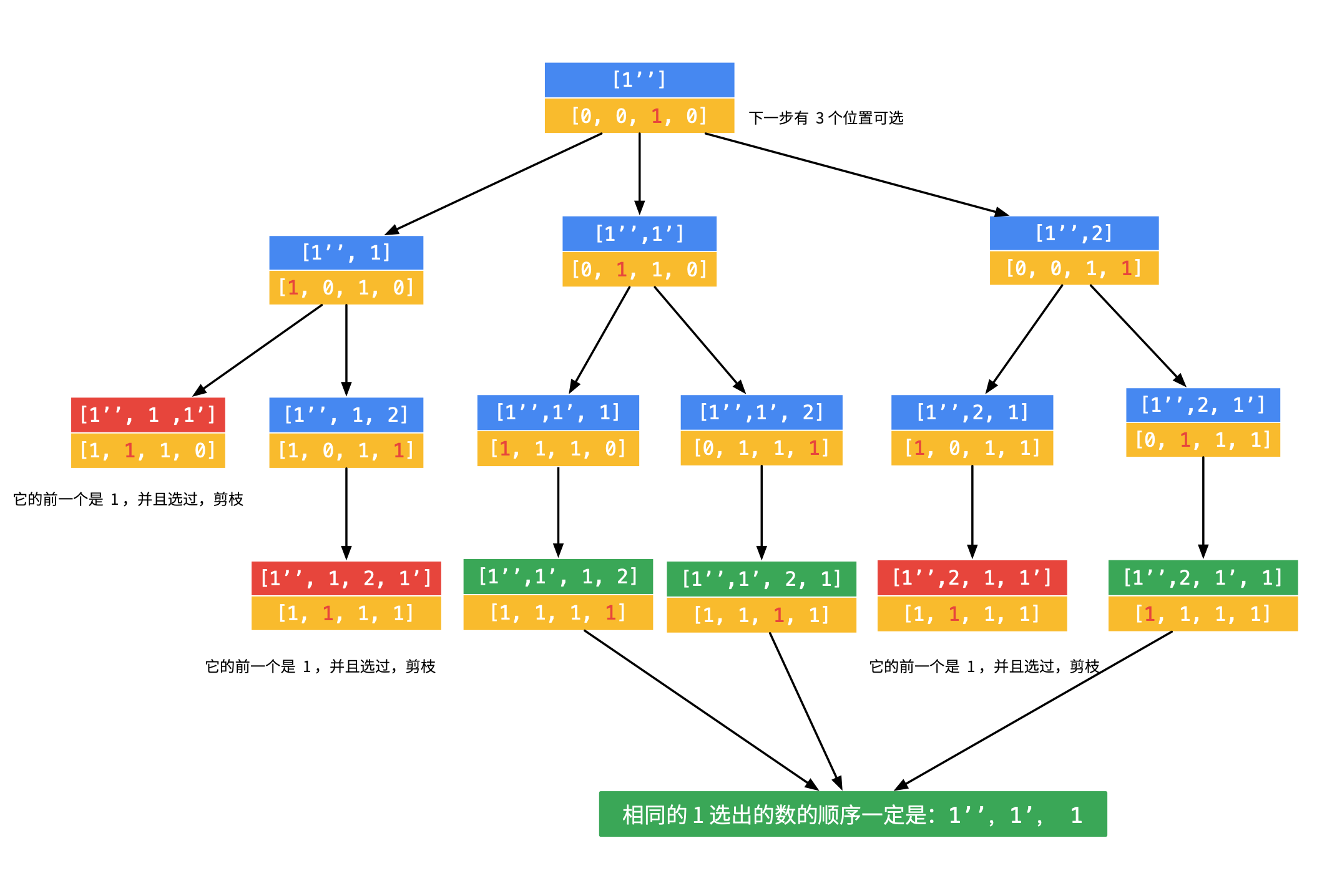
以 abb’c 为例,排列结果只可能出现 b’b,而不可能出现 bb’。
这两种剪枝都是可行的,但是第一种方式效率明显高于第二种。此外,虽然 used[j-1] 的取值可以是 true, 也可以是 false,但这并不意味着这个条件不重要,两个值只取其一都可以保证重复字符的固定顺序。
如果不加这个条件,则所有的重复字符情况都会被剪去,从上面两种方法的搜索树可以看出,有些重复字符情况不会产生重复排列结果。
代码
1 | class Solution { |
复杂度
- 时间复杂度 $O(nn!)$,其中 $n$ 为给定字符串的长度。需要 $O(nlogn)$ 的时间排序;这些字符的全部排列有 $O(n!)$ 个,每个排列平均需要 $O(n)$ 的时间来生成。因此总时间复杂度为 $O(nn!+nlogn)=O(n*n!)$。
- 空间复杂度 $O(n)$,使用数组、递归栈空间都是 $O(n)$。
方法二 下一个排列
对给定的字符串中的字符进行排序,即可得到当前字符串的第一个排列,然后不断地计算当前字符串的字典序中下一个更大的排列,直到不存在更大的排列为止即可。
注意到下一个排列总是比当前排列要大,除非该排列已经是最大的排列。因此要找到一个大于当前序列的新序列,且变大的幅度尽可能小。具体地:
将一个左边的「较小数」与一个右边的「较大数」交换,以能够让当前排列变大,从而得到下一个排列。
同时让这个「较小数」尽量靠右,而「较大数」尽可能小。当交换完成后,「较大数」右边的数需要按照升序重新排列。这样可以在保证新排列大于原来排列的情况下,使变大的幅度尽可能小。
代码
1 | class Solution { |
复杂度
- 时间复杂度 $O(nn!)$,其中 $n$ 为给定字符串的长度。需要 $O(nlogn)$ 的时间得到第一个排列,
nextPermutation函数的时间复杂度为 $O(n)$,至多执行该函数 $O(n!)$ 次,因此总时间复杂度为 $O(nn!+nlogn)=O(n*n!)$。 - 空间复杂度 $O(1)$,返回值不计。
